Data Warehouse Rules of Thumb: If you don’t know and can’t find out specifics, the following data warehouse rules of thumb are helpful (see the Practical Estimator column for definitions):
Cubes: Assume 1 cube per category of user or cluster of logically related data.
ETL: Assume 1 cube per dynamic source data table (1 batch per static source data table).
Portal: Assume 1 portal per category of system user (e.g., internal versus external, business versus consumer).
Predictive Model: 1 PM per forecast required, or if that is not known, guess 1 PM per category of user.
Universes: 1 universe per fundamentally different group of data (e.g., commercial lending versus retail demand deposit). |
|
|
| Level 4 received an estimation related contract with the Department of Homeland Security. |
|
|
All times are Pacific Time!
Free WebEx
Estimating with ExcelerPlan
7/9, 11 AM-12:30 PST
7/23, 11 AM-12:30 PST
8/13, 11 AM-12:30 PST
8/27, 11 AM-12:30 PST
9/10, 11 AM-12:30 PST
9/24, 11 AM-12:30 PST
To register for demos, email:
Jeff@portal.level4ventures.com |
|
|
Three Day Estimation Training
We’ll be offering a 3 day estimation training class taught by William Roetzheim via Webex on 8/4, 8/5, and 8/6. Class runs from 9 AM – 1 PM Pacific Time each day. Training is free and includes a 30 day trial license for new customers.
To inquire about registration email:
Jeff@portal.level4ventures.com |
|
|
Pay it Forward
Hopefully you’re finding ITCN a useful newsletter providing estimation related value added each month, along with a bit of humor and minimal selling. If so, please use the link below to Forward to a Friend, or if this copy was forwarded to you, to subscribe yourself.
Edward
Director of Sales and Marketing
|
|
|
|
|
| Sign up for a 3 day live Webex class, taught by William Roetzheim, to be conducted on 8/4-8/6 and receive a 30 day trial copy of ExcelerPlan. |
|
|
|
|
|
|

Who does estimation? Your organization is certainly doing IT estimation now, but do you know who is doing those estimates? Do you understand the implications of that choice? Let’s explore this issue a bit.
Vendors: A common approach to estimation is to rely on vendor estimates. If you receive 3 or more vendor quotes for a given job, the assumption is that the resultant vendor pricing is fair and reasonable. But what about using vendors for estimates in other situations. Vendor estimates that are provided as part of the market research stage of an acquisition are often prepared by the marketing department, and often reflect the vendor’s perception of the right number needed to get the acquisition moving forward. Vendor estimates of lifecycle costs at this stage will almost invariably be significantly understated. On the other hand, vendor estimates for change requests, sole source proposals, and actual maintenance and operations contracts are more likely to reflect “what the market will bear.”
Technical and Management Staff: You may rely on your internal technical and management staff for estimation. Although estimation is a complex technical skill, there’s a good chance that these internal estimators have never had formal training in estimation. Even with training, it takes 10 estimates to become competent and then 3 estimates per year to maintain proficiency. Your technical and management staff are probably too busy working on project delivery to have this level of involvement in estimation. And even if these barriers are overcome, there is a well-known bias toward underestimation when you are estimating effort for yourself or your own team.
Dedicated Professional Estimators: By using a smaller number of estimators to do all of your estimates, you can afford to invest in the necessary training; you avoid the estimator bias issue; and you ensure that the estimators will be doing sufficient estimates to develop and maintain the necessary skills. This can be accomplished using outside, contract estimators or by developing this skill set within an estimation center of excellence within your own organization.
|
| |
|
William@portal.level4ventures.com
|
|
|
 |
|
|
|
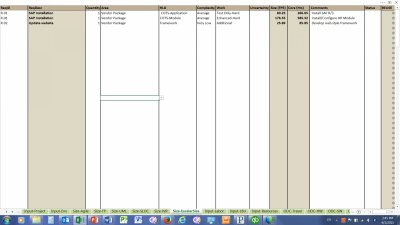
ExcelerSize: This month we continue our discussion of ExcelerSize, a Level 4 proprietary high level object (HLO) catalog set designed to size IT projects excluding purchased other direct charges (ODCs) such as hardware and software licenses (which are covered using separate models). You’ll recall that the catalog elements are grouped into five major categories:
- Project level sizing components that apply to the entire project.
- Application software sizing components.
- Data conversion sizing components.
- Data warehouse sizing components.
- Application support sizing components.
This month we’ll discuss data warehouse sizing components. A data warehouse a repository of extracted data that is used for reporting and analysis purposes. The data is copies of production data from other systems, and it is normally not real-time. Some advantages of a data warehouse versus direct access to production data include: 1. Data can be pulled from a variety of external systems and consolidated in the data warehouse. 2. The Data warehouse can impose a consistent data naming taxonomy without requiring changes to the source systems. 3. CPU/IO intensive queries will not adversely impact production performance. 4. Cross platform/system data relationships become visible. 5. Data warehouses insulate production data from intentional (e.g., hacker) or unintentional contamination. The following sizing components are used to estimate data warehouse specific effort:
- Cubes or online analytical processing (OLAP) Datamarts. A cube is a multi-dimensional collection of data that is related from a business perspective. Cubes were created to allow business users to easily generate ad hoc queries and reports that slice and dice the data in different ways.
- Extract-Transform-Load processes. ETL processes are how the data warehouse obtains data from source systems. Transforms may include cleaning, filtering, validation, splitting, joining, derivations, or business rules.
- Portals. A portal is a user interface framework where user interaction components live.
- Predictive Models. Each predictive model accepts independent variable inputs, applies a model, and generates one or more dependent output values. Examples of models include Bayesian statistical models, neural networks, genetic algorithms, and power functions. Examples of business use include SPAM filtering, revenue forecasts, fraud detection, cost estimating. Remember that cubes look backward, predictive models forward.
- Universes. A universe is a semantic layer that collects and defines the available data in a more business friendly fashion. It shields the business analyst and user from the details of how the data is stored.
In addition to these data warehouse specific HLO components, you’ll use the normal application components where they apply. For example, your data warehouse estimate will normally include pages and reports. Next month we’ll continue this discussion, talking about application support sizing components.
|
|
|
|
|
[This guest column reprinted with permission from: “MINIMIZING THE RISK OF LITIGATION: PROBLEMS NOTED IN BREACH OF CONTRACT LITIGATION,” Capers Jones, July 2014. Full article available on http://Namcookanalytics.com]
[Editor: This column continues the discussion of litigation risk factors from last month’s edition.]
The High Costs and Business Interruptions Caused by Litigation
Breach of contract litigation is an expensive business activity and also one that requires hundreds of hours of executive time, thousands of hours of technical staff time, and hundreds to thousands of billable hours by litigation attorneys and by paralegal and support personnel.
From noting the high costs for both the plaintiffs and defendants in breach of contract litigation, the Namcook Analytics Software Risk Master ™ (SRM) tool includes a standard feature for predicting breach of contract costs for both the plaintiff and defendant. The costs assume the case goes through trial. Out of court settlements are random and unpredictable. The high costs of litigation make clear the need for both excellence in outsource contracts and also professionalism in software development methods. Software projects are unfortunately also susceptible to several other kinds of litigation including but not limited to:
• Patent violations from patent trolls
• Patent violations from legitimate patent holders
• Litigation for bias in civilian and defense contract awards
• Theft of algorithms and code from business competitors
• Non-competition and employment agreement issues
• Fraud charges from dissatisfied clients
• Possible damages from harm done by software in cases such as brake failures
• Possible criminal charges for Sarbanes-Oxley violations
Attorneys and legal costs are a steadily increasing source of expense for modern software applications, and especially for those in contentious and litigious technical fields such as telecommunications, social networks, and novel human interface methodologies.
More serious kinds of litigation can occur for software that controls physical devices such as medical equipment, avionics packages, weapons systems, and automotive controls where software failures can cause injury or deaths.
Next month, Summary and Results.
Capers
|
|
|
|
 Dear Tabby: Dear Tabby:
My boyfriend speaks a new language that was recently developed. This makes it difficult to estimate how long anything will take because I don’t have any experience with this language. Should I just give up and get a new boyfriend?
signed, Linguist in Las Vegas
Dear Linguist:
Many of the earlier source lines of code (SLOC) estimating models were heavily language dependent. Those models focused on programming effort when estimating work requirements, and they assumed that the code was written by programmers. Today’s applications tend to consist of a mixture of several languages (e.g., Java, PERL, SQL, XML); tend to have a mixture of machine generated and programmer generated code; and the programming itself is an increasingly small part of the overall effort. For this reason, most newer models focus on delivered business functionality, and assume that a suitable implementation approach will be used to create that functionality. So the estimator can, in effect, ignore language when estimating.
signed, Tabby
|
|
|
|
|
|
ExcelerPlan Version 7.2
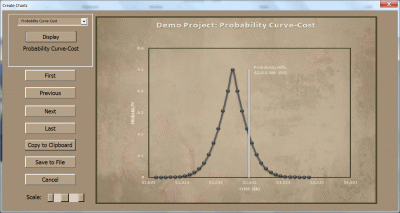
Version 7.2 is now shipping, with support for export to a variety of formats (MS Project, Excel, Clarity, XML, and CSV). In addition, ExcelerPlan now allows you to enter a desired confidence level (probability) for the estimate of size, effort, and cost; and it will then create the estimate outputs at that confidence level. For example, by default the estimates will be created at the 50% confidence level (peak of the probability curve). But suppose you have a project where it is much easier to give money back than to request more money? You might want to base your estimates on the 80% confidence level.
|
|
|
|
|
|